Standard Forward Pass (Depth 1)
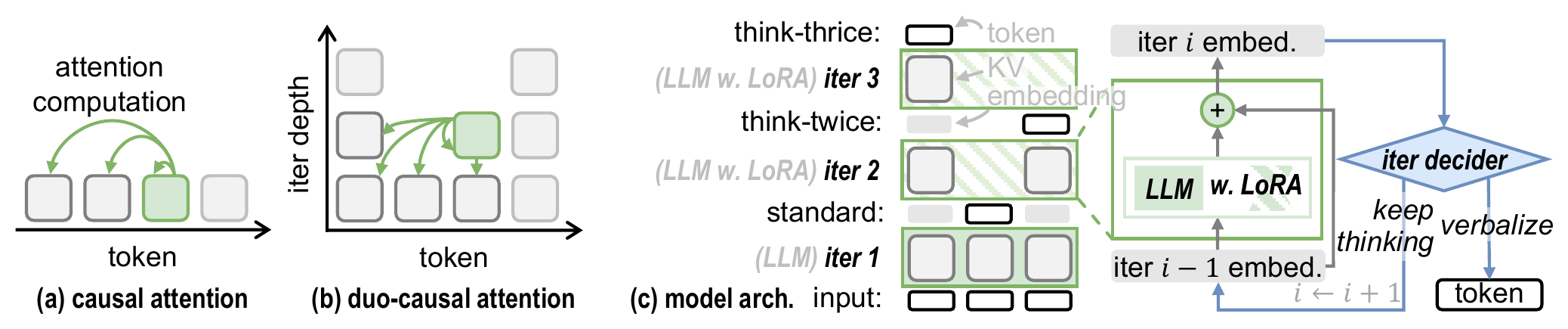
Token embeddings enter the LLM backbone for a standard forward pass at depth $d=1$. The model uses its original pretrained weights $\theta$ without any LoRA adaptation. This first iteration produces standard next-token predictions — correct for ~93% of tokens.
Key: The first pass preserves the pretrained model's strong next-token prediction ability. Only hard tokens proceed to deeper iterations.
Duo-Causal Attention
Unlike standard causal attention (1D: attend to previous positions), duo-causal attention extends causality to two dimensions: tokens attend to both previous positions and shallower iteration depths. Formally: $X_{\le i}^{(\le d)} = \{x_j^{(k)} \mid j \le i, k \le d\}$.
Key: This enables cross-depth information flow — deeper tokens can access shallower representations of all previous tokens — while maintaining full parallel training via FlashAttention compatibility.
Depth Adapter (LoRA)
At deeper iterations ($d > 1$), LoRA adapters activate on top of the shared backbone: $\theta_d = \theta + \Delta$. This shifts the model's objective from general next-token prediction to focused hard-token refinement. Residual connections across iterations simplify the refinement process.
Key: LoRA adds less than 3% extra parameters while enabling the model to specialize deeper iterations. Without LoRA, the shared weights must handle both objectives, limiting performance.
Neural Iteration Decider
A lightweight MLP ($\mathcal{I}_\phi$) reads concatenated hidden states from shallow, middle, and final LLM layers to predict a continuation probability $\hat{c}_i^{(d)} \in [0,1]$. If $\hat{c}_i^{(d)} < c_{\text{threshold}}$, the token verbalizes; otherwise it continues to the next iteration depth.
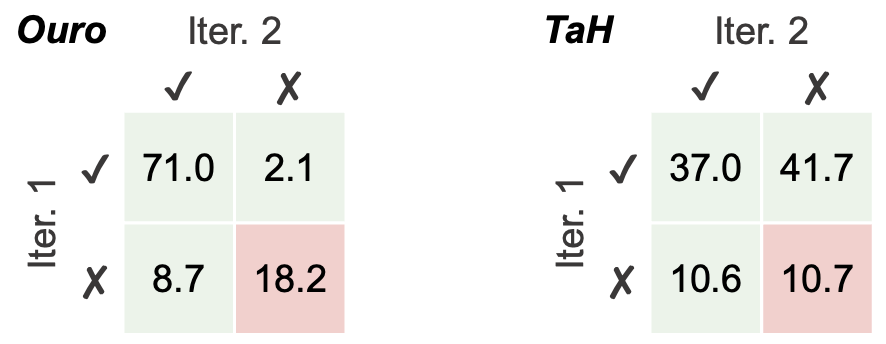
Key: The decider is trained in Stage 2 to imitate the oracle policy via weighted binary cross-entropy. It achieves ~83% accuracy at predicting the oracle's decisions. Tokens like "But" (34%) and "So" (18%) are most frequently selected for deeper iteration.